
I recently had a requirement to take many pieces of data from D365FO, create a CSV file out of each data piece, and then wrap these files in a zip file for easy downloading by an end user. In my case, the requirement was that all of the data should be held in memory (never written to disk). I wanted to show the process of how I achieved this.
Test Scenario
To show how I did this I will be using the test scenario of taking all customer and vendors from a D365FO envrionment, writing them each to a CSV, and then committing both to a zip file for an end user to download.
To perform this, I set up a solution with both an X++ and .NET project (the reason for this will be explained later on). I then created a form with a button to generate the zip file. The code flow for this project is that it will start on the X++ side based on a button click to generate the data we want to store in the zip file, then this data will be sent to our .NET project to generate the individual CSV files and then commit the CSV files to the zip file before returning a MemoryStream of the zip file itself, the final step is back in X++ to utilize the File::SendFileToUser method which consumes this MemoryStream to prompt the user to download the zip file in their browser.
X++ Side
On the front end I created a simple form with an Export Zip button.
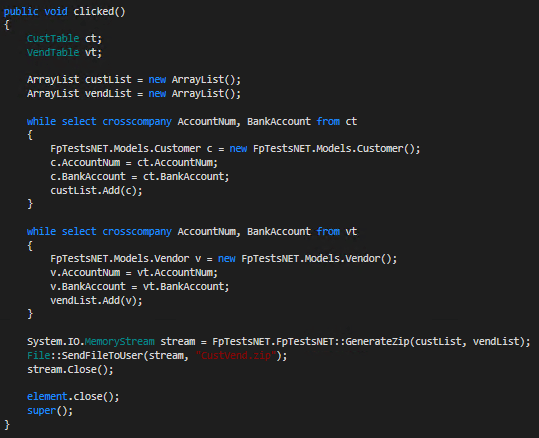
On the X++ form code, I created a clicked() event for the button which gathers the data we would like to save and storing each in its own ArrayList. Once this is completed we then call our .NET method to generate the zip file taking in the created ArrayLists.
.NET Side
On the .NET side, we convert the ArrayLists to actual .NET lists, then create the individual CSV files by using the CsvHelper nuget package. One thing to note here is that we create each CSV using its own MemoryStream. We save each stream by using a helper object I created (CsvFile) which stores the file name as well as the MemoryStream itself.
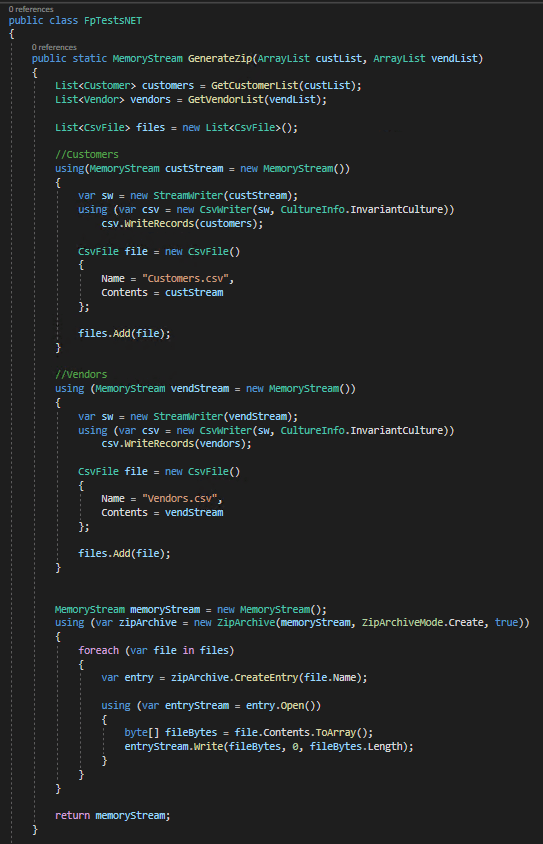
Once we have MemoryStreams of each file we want to save to the zip file, we can then turn to actually creating the zip file itself. To do this I utilize the built in ZipArchive class. We then loop through each CSV file and create an entry in the zip file using the file name and MemoryStream stored earlier. One thing to note here is that we do not use a ‘using’ statement on this particular MemoryStream, this is because we have to pass this open MemoryStream back to the X++ side to download the file. If you place a using statement around this the stream, it will be closed and unable to be sent to a user later on.
So why do we use a .NET project for this at all? There are a number of reasons for me to do this:
- While I’m certain that all of this logic could be done in X++, I am a .NET developer by trade and much more comfortable writing in that language
- It also makes it easier to troubleshoot later on as there are more .NET developers on our team than X++ developers
- I find the way that .NET treats data collections to be much easier to interact with than X++
- You get the added ability to easily use Nuget packages if needed (the ecosystem of .NET nuget packages is massive)
Now that we have the MemoryStream back on the X++ side, we can call the File::SendFileToUser method to prompt the user to download the file. One thing to note here is that after this method we need to close the MemoryStream.
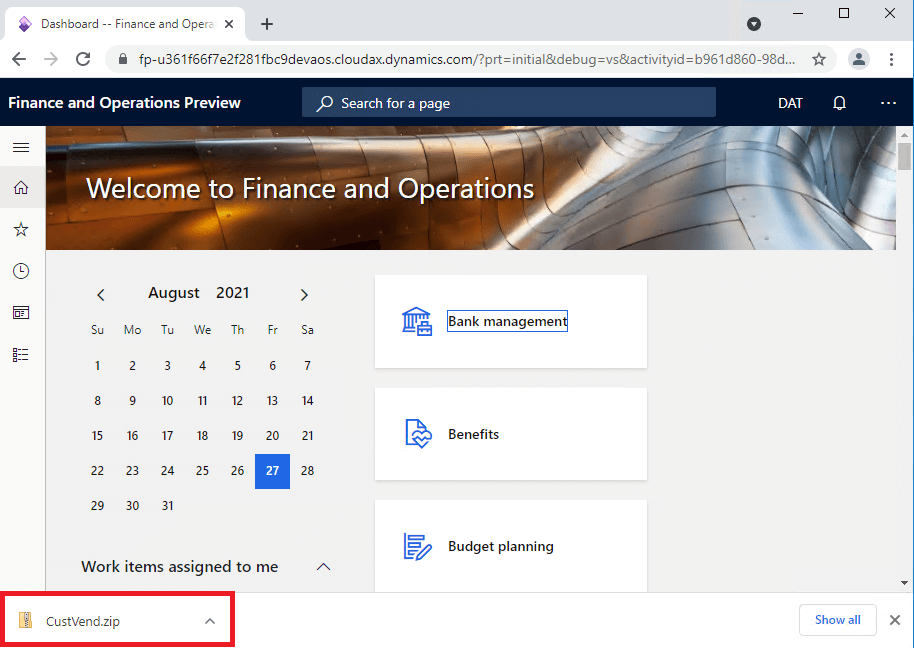
If we open the zip file we can see the individual Customer and Vendor CSV files.
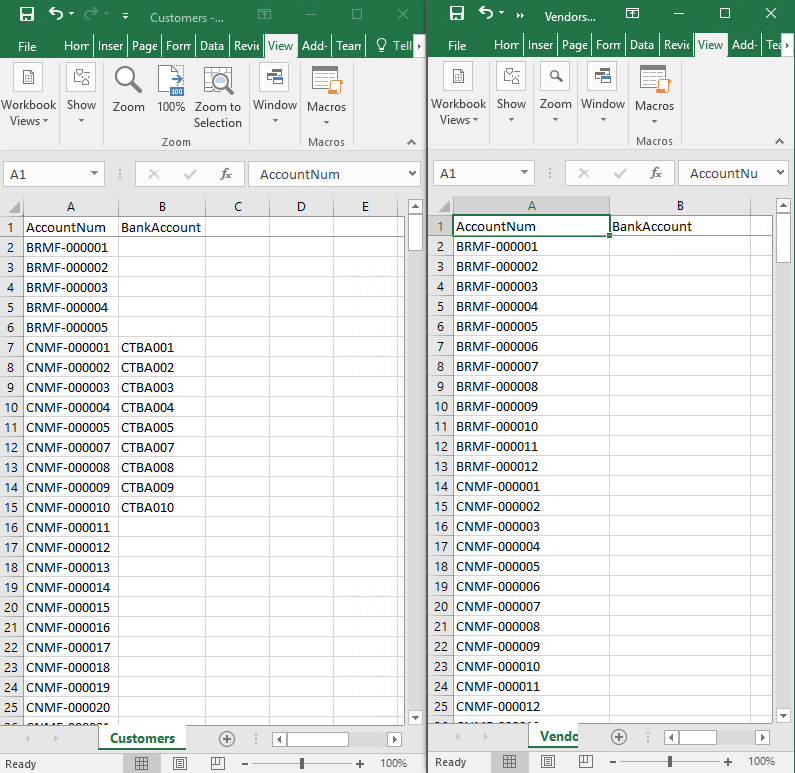
If we open the CSV files we can see the data is correctly being displayed:
YouTube Overview
I recorded a YouTube video explaining the code in depth and showing the test solution in action: Creating a Zip File from Multiple MemoryStreams in D365FO
Takeaways
- Although I used CSV files above in my test scenario, this solution would also work for other file types (XLSX, JSON, XML, etc) as long as you can get them into a Stream object (or an object that implements the Stream object).
- This solution shows that the data you put into the zip files does not need to be stored as a physical file to be able to be exported and instead can be kept in memory
Hello Alex,
I have created .dll, whenever I try to use this dll in D365 FinOps my project that time below error occurs:
Could not load file or assembly ‘CsvHelper, Version=27.0.0.0, Culture=neutral, PublicKeyToken=8c4959082be5c823’ or one of its dependencies. The system cannot find the file specified.
Regards,
Ashik Patel
Ashik,
CsvHelper is a nuget package that needs to be added to your .NET project: https://joshclose.github.io/CsvHelper/